Advanced regular expression features to match Markdown links
This step by step article will introduce you to some more advanced features of regular expressions:
- Non-capturing and named groups.
- Recursive regular expressions.
- Free spacing mode.
- Lookbehind for whitespace.
We will make use of these features with a real world example to match complex Markdown links such as this one:
[Link text with [brackets] inside](http://www.example.com "My \"title\"").
Our goal is to find such links and to extract the following information from them:
- Text (
Link text with [brackets] inside). - URL (
http://www.example.com). - Optionnel title (
My "title").
All schemas illustrating the steps of this article are generated using the excellent Debuggex website. Reading complex regular expressions is much easier and you can test strings directly in the interface, so I highly recommend this tool.
Do not forget to enable PCRE (Perl style) regular expressions and to activate the x flag (I will explain this in the article) in the interface:
Let's start with a simple regex
Writing a regular expression that matches Markdown links in a string can seem to be straightforward. We can translate the pattern that we see as humans to a regex: square brackets with text inside followed by parentheses with text inside and possibly followed by a space and some text between double quotes.
This gives the following regex:
\[(.+)\]\(([^ ]+?)( "(.+)")?\)
This is how the regular expression schema looks on Debuggex:

There are 4 capturing groups (surrounded by parenthesis) in that regex:
- Group 1 is the text of the link.
- Group 2 is the URL of the link.
- Group 3 is the optional title of the link including the double quotes (this group is necessary for the
?marker). - Group 4 is the optional title of the link.
We will see that this naive way to solve the problem has several limitations, leading to a more complex regular expression that gets harder to read. We are first going to improve its readability and then tackle the shortcomings of it.
Step 1: improve readability
Regular expressions are quite cryptic to read. So just like for code, let's be nice to your future-you or your colleagues who will read your regular expression and make it the clearest possible.
Let's first have a look at the different matches on the regular expression on the [My text](http://www.example.com "My title") string. Let's do it with PHP (but this could be done with any language):
<?php
$regex = '\[(.+)\]\(([^ ]+)( "(.+)")?\)';
$subject = '[My text](http://www.example.com "My title")';
preg_match("`$regex`", $subject, $matches);
echo json_encode($matches, JSON_PRETTY_PRINT);
This is the output (JSON format):
[
"[My text](http://www.example.com \"My title\")",
"My text",
"http://www.example.com",
" \"My title\"",
"My title"
]
Use non-capturing groups to remove useless groups in the output
➡️ Syntax: (?:...) instead of (...) for a normal group.
Any group used solely for technical reason in the regular expression should not be part of the output. This is where non-capturing groups get useful to improve the readability of the result, but not the regular expression itself.
In the example above, the group showing the title between double quotes ("My title") is not useful, as we just want to extract the title itself, and not the Markdown syntax. This is the group we are going to remove in the output by using a non-capturing group.
\[(.+)\]\(([^ ]+)(?: "(.+)")?\)
We now have only 3 groups left instead of 4 and the new output is as follow:
[
"[My text](http://www.example.com \"My title\")",
"My text",
"http://www.example.com",
"My title"
]
Use named groups
➡️ Syntax: (?<groupname>...)
Groups are indexed numerically by default in the output, which comes with two problems:
- If you add one group in the middle of your regular expression, all next group indexes will be shifted, which will introduce regressions in your code.
- Numbers are hard to read: you always have to count how many non-escaped parentheses to know the group number.
Named groups will improve both the output and the readability of the regular expression.
Let's name our groups in the current regex using this new group syntax:
\[(?<text>.+)\]\((?<url>[^ ]+)(?: "(?<title>.+)")?\)Here is the new output with PHP (would be the same with any other language):
{
"0": "[My text](http://www.example.com \"My title\")",
"text": "My text",
"1": "My text",
"url": "http://www.example.com",
"2": "http://www.example.com",
"title": "My title",
"3": "My title"
}
Amazing! We now have direct access to the URL, title and text with named indexes in addition to numbered indexes!

Add comments and go multiline with the x modifier!
🎆 This little tip is magic. It will allow you to:
- Add comments in your regular expressions (just as you do it to explain complex code).
- Seperate things nicely in a multiline expression and use indentation.
All you have to do is to use the x modifier in your regular expression. When this modifier is set, whitespace data characters (including new line character) in the pattern are totally ignored and comments can be addeded after a #.
There is one small downside to this. Now that spaces and line returns are ignored, how can you capture spaces? Here is the trick: explicitly look for space using [ ], between square brackets.
Let's update our regular expression with indentation, line returns and comments:
\[
(?<text>.+) # Text group
\]
\(
(?<url>[^ ]+) # URL group
(?: # Group matching title with space and double quotes around
[ ] # Space separating URL and optional title
"
(?<title>.+) # Title group
"
)? # Title group is optional
\)Our regular expression is now much easier to read and maintain.
Step 2: fix title matching with a look behind expression
Double quotes enclose titles (eg. "title"). But a title can also contain double quotes if they are escaped with a backslash: "This is \"my title \"". A title string is therefore defined as a string of:
- Non double quotes characters.
- Or a double quotes characted that is preceded by an antislash (escaped double quotes).
We are going to use a positive look behind expression to find escaped double quotes.
➡️ Syntax of positive look behind expression: (?<=foo)bar (finds "bar" only if preceded by "foo").
In our case, finding escaped double quotes will look like this: (?<=\\)" (the backslash has to be escaped itself in the regex, hence the double backslash).
We can now replace the title group by:
(?<title>(?:[^"]|(?<=\\)")*?)The whole regular expression becomes:
\[
(?<text>.+) # Text group
\]
\(
(?<url>[^ ]+) # URL group
(?: # Optional group matching title with space and double quotes around
[ ] # Space separating URL and optional title
"
(?<title> # Title group
(?:
[^"]|(?<=\\)"
)*?
)
"
)?
\)A link like this will now be correctly matched: [My text](http://www.example.com "My \"title\"").
Step 3: Use recursive regular expressions for complex text matching
Our current regular expression to match markdown links works well so far, but not in all cases. Let's consider the following markdown link, which is valid too: [Link text with [brackets] inside](http://www.example.com).
💥 The text part now contains somes brackets in its content, something that our current regex doesn't handle!
Again, how we would do it as a human? While reading the string from left to right, we would count the number of opening square brackets and the number of closing ones, so that we know what is the last closing bracket corresponding to the first opening one.
In other words, we are looking for encapsulated groups consisting strings with the following form: [ ... ]. This is the exact definition of recursion!
We will use the special syntax (?&name_of_block) to look recursively for the name_of_block block pattern.
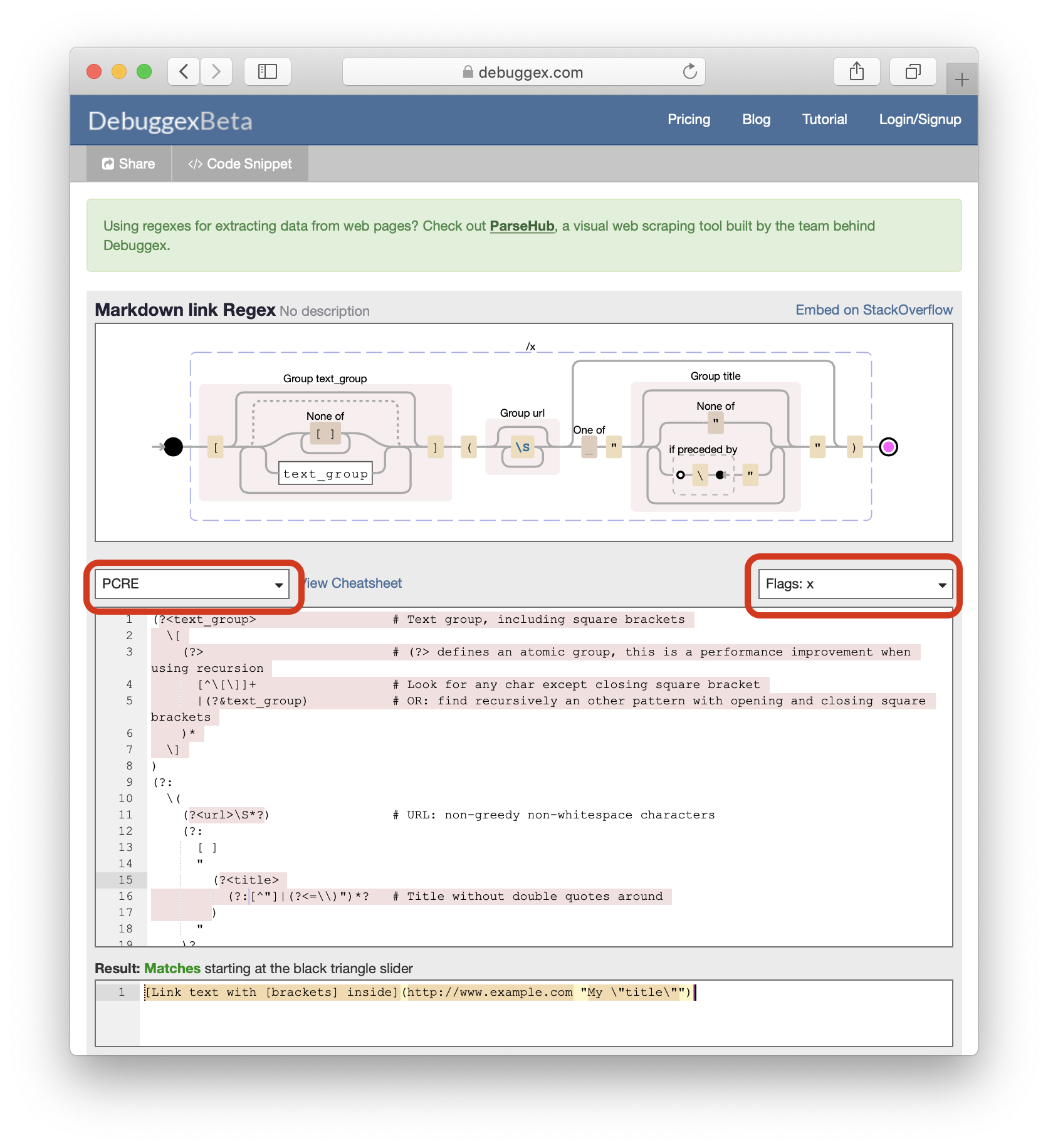
So here is our final regular expression to match a Markdown link:
(?<text_group> # Text group, including square brackets
\[
(?> # (?> defines an atomic group, this is a performance improvement when using recursion
[^\[\]]+ # Look for any char except closing square bracket
|(?&text_group) # OR: find recursively an other pattern with opening and closing square brackets
)*
\]
)
(?:
\(
(?<url>\S*?) # URL: non-greedy non-whitespace characters
(?:
[ ]
"
(?<title>
(?:[^"]|(?<=\\)")*? # Title without double quotes around
)
"
)?
\)
)We now have a regular expression that matches Markdown links, extracts their data and that's easy to read! 🥳
Here is the final schema for the regular expression:
